
Abstract:
As the saying goes: the past causes the present and influences the future.
This interrelation between past, present, and future is key to using the past as a mirror to look into the future. This is of immense significance for both individuals and organizations. And it is the secret to getting your company’s future ready. There are just four steps you need to take, here they are :
History & Problem Statement:
The world has been using data warehouses on premises since the 1980’s. Thereafter we have been evolving in managing structured data, which has been designed to ensure the ease of querying the information in the most efficient manner. Now when it is about managing exponentially growing data, there have been few concerns. We started moving towards cloud-based architecture and reducing certain risks of data failures and quick scalability as per the need.
With this, there are certain pain points that an organization must bear in mind while making long-term plans, starting with the cost of stale data and redundancy, extreme scalability, data quality, integration, data governess, analytics and integration/managing with rich data like photos/videos/audio files etc.
All the above-mentioned concerns and risks can be mitigated by gradually migrating towards the Data Lakehouse.
As you can see, historical data (your past) holds the key to understanding your performance and deciding whether you should continue what you are doing or make any course corrections for a better future.
Data that you need for this introspection will come from various enterprise systems like General Ledger, Sales & Marketing System, Asset Management System, Customer Relationship Management System, HR/Payroll System, and various other mission-critical systems on which your business is dependent.
Data management & data visualization can play a major role in dissecting your historical data and preparing for the future.
Historical Transition of ETL Architecture:
First Gen- Data Warehouses:
First-generation data warehouses and storage have had a long history of supporting decision-making and business intelligence activities, but they weren’t well suited or particularly capable of handling unstructured data, semi-structured data, and data with a lot of diversity and volume.
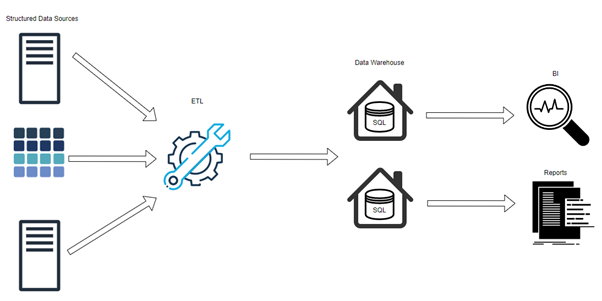
Current Two-Tier Data Architecture:
Large amounts of natively formatted organized, semi-structured, and unstructured data are kept in a data lake. As data quantities have increased, data lake architecture has changed in recent years to better match the needs of businesses that are becoming more and more data driven.
Additionally, well-known SQL tools can be used to operate the contemporary data lake environment. The current data lake platform’s internal storage objects and necessary compute resources allow for speedy data access and quick, effective analyses. This is very different from historical designs, when data had to be moved to a different storage-compute layer for analytics and was stored in an external data bucket, slowing down the pace at which insights could be gained as well as overall performance. Hence, a custom hybrid architecture was introduced after the traditional data warehouse.
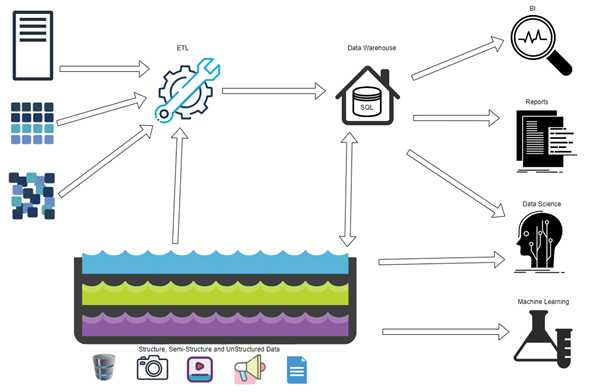
Data Lakehouse Detailing:
Data lakes and data warehouses are two well-known ideas in the field of data that have recently attracted a lot of attention. What if we could combine the advantages of both worlds? The idea of a data lakehouse is useful in this situation.
A centralized and integrated data platform called a “data lakehouse” combines the scalability and flexibility of data lakes with the greater dependability and querying power of data warehouses. You can store and analyse data in its unstructured, raw form using this architectural pattern, and you can also alter and arrange that data for business intelligence and data analytics.
Data is initially fed into a data lake in a data lakehouse architecture, where it is then stored in its unprocessed state. Following processing, transformation, and enrichment, this raw data is subsequently put into a data warehouse for analysis. While maintaining the capacity to run complicated queries and analyses of structured data in the data warehouse, this architecture enables businesses to benefit from the low-cost storage and scalability of data lakes.
A data lakehouse’s ability to accept data from several sources, including structured, semi-structured, and unstructured data, is one of its main advantages. Since it can handle large amounts of data, including streaming data and real-time data streams, it is the perfect platform for this.
Agile analytics and data processing are other advantages of a data lakehouse. Data may be handled and modified on the fly without the use of pre-defined schemas or data models because it is stored in its raw form in the data lake. This makes it possible for businesses to react swiftly to shifts in accordance with business needs and conduct real-time data analysis.
Data scientists, analysts, and business users can all access a data lakehouse’s unified view of all the data within an organization. This breaks down data silos and makes it possible for businesses to learn from all their data, regardless of its origin or format.`
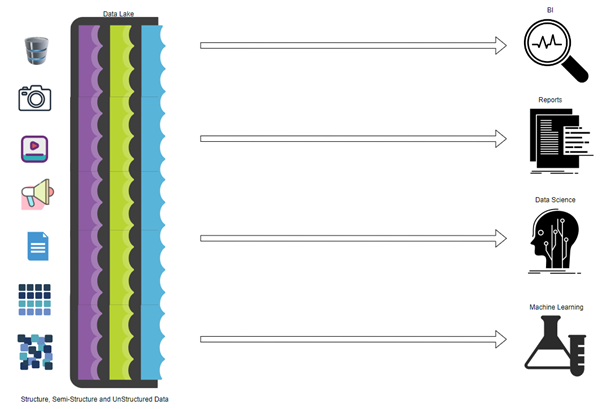
Compare – Data Lakehouse v/s Data warehouse v/s Data Lake:
To scale to the potential of your organization tomorrow, your data architecture must change to accommodate the demands of your business. What is good about that? You have more options than just a low-cost enterprise data swamp or a constrained, rigid data consumption machine for data management. Data warehousing only ingests structured data without offering you the flexibility or scalability for your expanding organizational needs.
SQL applications and business intelligence are supported by data warehouses, which are expensive and unable to consume semi-structured or unstructured data, despite being effective and safe. Simply put, they weren’t designed for today’s robust and rich data challenges.
All forms of data can now be handled by data lakes, which also offer less expensive storage. Additionally, data lakes were able to support data science and machine learning skills. Unfortunately, they lacked a crucial component of data warehouses: They do not enforce data quality and governance or support ACID transactions, which makes working with this data clumsy and time-consuming.
That’s why it is important to ensure that data is correctly curated and managed throughout its lifecycle, from ingestion to analysis, which is one of the toughest problems. This necessitates proficiency in data modelling and data integration, as well as a thorough awareness of the data and the analytical needs of the organization. This further necessitates a strong data governance policy with guidelines for privacy, data security, and quality and that’s where Data Lakehouse brings ease to the current Data Management Architecture.
The following essential qualities define a data lakehouse:
Support for transactions:
Many data pipelines will frequently be reading and writing data simultaneously in an enterprise lakehouse. Consistency is ensured when several parties use SQL to read or write data concurrently using support for ACID (atomicity, consistency, isolation, and durability) transactions.
Openness:
They employ open, standardized storage formats like Parquet and offer an API so that a wide range of tools and engines, such as machine learning and Python/R libraries, can effectively access the data directly.
Schema governance and enforcement:
The lakehouse ought to provide a method for facilitating schema evolution and enforcement, enabling DW schema topologies like star/snowflake-schemas. In addition to having strong governance and auditing methods, the system should be able to reason about data integrity.
Storage and computation are separated:
Allowing these systems to scale to support many more concurrent users and bigger data volumes. This implies using distinct clusters for storage and computing. This characteristic is present in some contemporary data warehouses.
BI assistance:
Using BI tools directly on the source data is made possible by data lakehouses. This saves the expense of needing to operationalize two copies of the data in a data lake and a warehouse. It enhances recency, reduces staleness, and lowers latency.
Support for a variety of data:
Rich Data like images, videos, audio, semi-structured data, and text are just a few of the data types that may be stored, improved, analyzed, and accessed with the lakehouse.
End-to-end streaming:
In many businesses, real-time reporting is the norm. Support for streaming renders unnecessary the use of separate servers for real-time data applications.
Affordable storage: As data volumes rise,
storage grows proportionally; and in order to limit latency, the cost goes up even higher, hence it is important to have an affordable data storage solution.
All data types and file formats are supported:
Support for multi-descriptive/informative data formats including both unstructured and structured is also supported through csv, avro, parquet, etc. This also reduces costs by storing data in its native/original format. This means that you don’t have to convert the data into a format that can be read by a traditional database.
Access to data science and machine learning tools is improved:
To analyze the data pattern, having data science and machine learning experiments are highly important for reasons of growth, and access should be easy while the data is used in production.
Centralization:
Using a single system instead of multiple systems will enable your data teams to move workloads more quickly and correctly.
Real-time streaming:
Capabilities for projects including data science, machine learning, and analytics in real-time.
Flexibility and scalability:
Allowance of a procedure or system to monitor work in the warehouse, enabling expansion of the warehouse.
Blog Conclusion:
A robust foundation for managing and analyzing data is offered by a data lakehouse architecture. Organizations may acquire insights from all their data and swiftly adapt to changing business needs by combining the scalability and flexibility of data lakes with the dependability and querying capabilities of data warehouses. A solid data governance policy, as well as knowledge of data modelling and integration, are necessary for successfully deploying a data lakehouse.
References:
[1] https://www.databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
[4] https://www.cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf
[5] https://www.youtube.com/watch?v=cnCIoNDaGvg
[7] https://www.snowflake.com/guides/what-data-lakehouse
[8] https://www.talend.com/resources/what-is-data-lakehouse/